Research
My research interests lie in generative models, with a particular focus on video generation. My long-term goal is to develop generative models capable of simulating the real world—and imagining beyond it.
Your browser does not support the video tag.
Video4Spatial: Towards Visuospatial Intelligence with Context-Guided Video Generation
Zeqi Xiao ,
Yiwei Zhao ,
Lingxiao Li ,
Yushi Lan ,
Ning Yu ,
Rahul Garg ,
Roshni Cooper ,
Mohammad H. Taghavi ,
Xingang Pan
arXiv , 2025
project page
Your browser does not support the video tag.
WorldMem: Long-term Consistent World Simulation with Memory
Zeqi Xiao ,
Yushi Lan ,
Yifan Zhou ,
Wenqi Ouyang ,
Shuai Yang ,
Yanhong Zeng ,
Xingang Pan
NeurIPS , 2025
project page
/
arXiv
/
code
/
demo
/
bibtex
Your browser does not support the video tag.
TokensGen: Harnessing Condensed Tokens for Long Video Generation
Wenqi Ouyang ,
Zeqi Xiao ,
Danni Yang ,
Yifan Zhou ,
Shuai Yang ,
Lei Yang ,
Jianlou Si ,
Xingang Pan
ICCV , 2025
project page
/
arXiv
/
bibtex
Your browser does not support the video tag.
Alias-Free Latent Diffusion Models: Improving Fractional Shift Equivariance of Diffusion Latent Space
Yifan Zhou ,
Zeqi Xiao ,
Wenqi Ouyang ,
Shuai Yang ,
Xingang Pan
CVPR , 2025 (Oral)
project page
/
arXiv
/
code
/
bibtex
Your browser does not support the video tag.
Trajectory Attention For Fine-grained Video Motion Control
Zeqi Xiao ,
Wenqi Ouyang ,
Yifan Zhou ,
Shuai Yang ,
Lei Yang ,
Jianlou Si ,
Xingang Pan
ICLR , 2025
project page
/
arXiv
/
code
/
bibtex
Your browser does not support the video tag.
Video Diffusion Models are Training-free Motion Interpreter and Controller
Zeqi Xiao ,
Yifan Zhou ,
Shuai Yang ,
Xingang Pan
NeurIPS , 2024
project page
/
arXiv
/
code
/
bibtex
CooHOI: Learning Cooperative Human-Object Interaction with Manipulated Object Dynamics
Jiawei Gao *,
Ziqin Wang *,
Zeqi Xiao ,
Jingbo Wang ,
Tai Wang ,
Jinkun Cao ,
Xiaolin Hu ,
Si Liu ,
Jifeng Dai ,
Jiangmiao Pang
NeurIPS , 2024 (Spotlight)
project page
/
arXiv
/
code
/
bibtex
Your browser does not support the video tag.
UniHSI: Unified Human-Scene Interaction via Prompted Chain-of-Contacts
Zeqi Xiao ,
Tai Wang ,
Jingbo Wang ,
Jinkun Cao ,
Wenwei Zhang ,
Bo Dai ,
Dahua Lin ,
Jiangmiao Pang
ICLR , 2024 (Spotlight)
project page
/
arXiv
/
code
/
bibtex
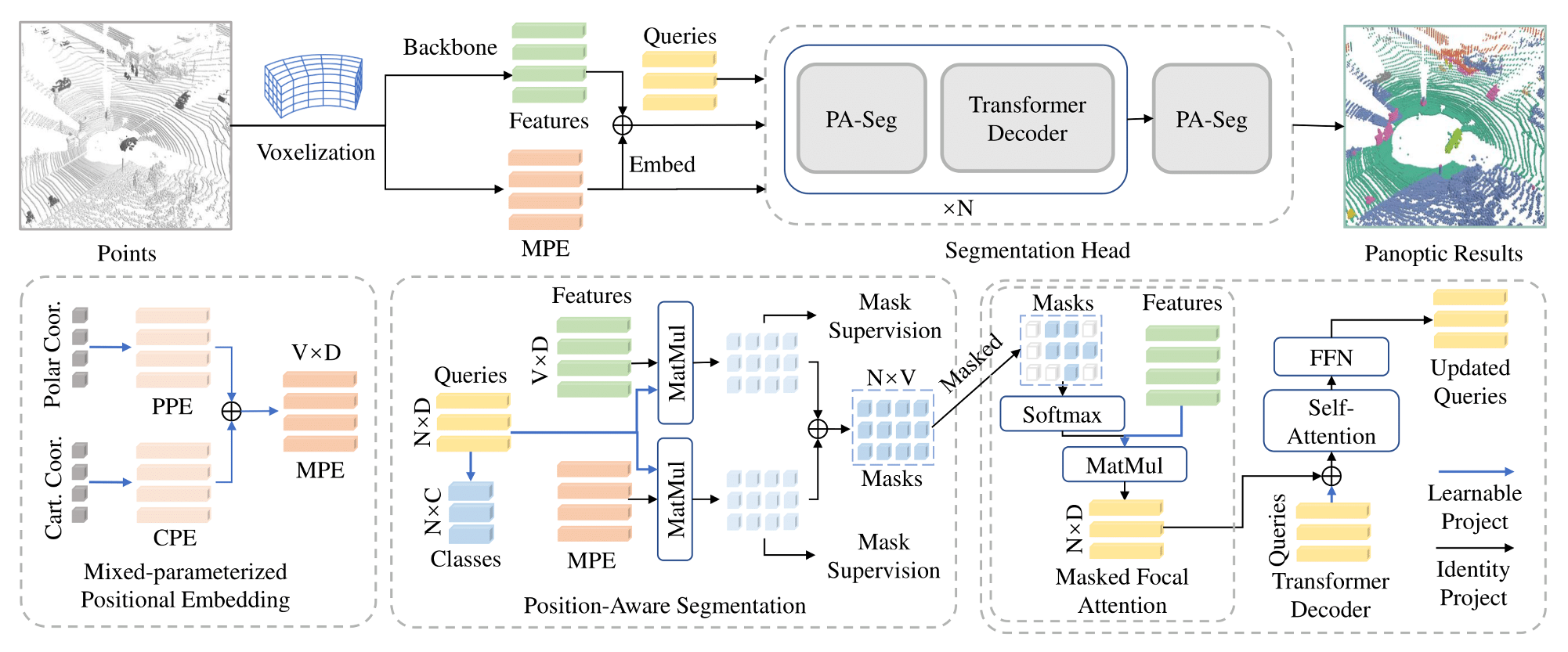
Position-Guided Point Cloud Panoptic Segmentation Transformer
Zeqi Xiao *,
Wenwei Zhang *,
Tai Wang *,
Chen Change Loy ,
Dahua Lin ,
Jiangmiao Pang
IJCV , 2024
arXiv
/
code
/
bibtex